THE CALCULATION OF TIME DOMAIN FREQUENCY STABILITY
W.J. Riley, Hamilton Technical
Services
This paper describes a test suite to check the accuracy of frequency stability analysis software. It contains the values of several common statistics and frequency stability measures for two data sets, a small one suitable for manual entry, and a larger one produced by a portable pseudo-random number generator. The paper also discusses related issues such as data gaps and outliers, conversions, drift removal, numerical precision, plotting and simulation. It is a revised version of two papers [20, 21] presented at the IEEE International Frequency Control Symposium.
Click on the following links to go to the corresponding sections of this paper.
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
|
INTRODUCTION
Specialized calculations are necessary to express the results of time domain frequency stability measurements [1, 2, 3]. A common example is the Allan variance for a set of fractional frequency data. Such calculations are generally performed by a computer, for which a custom program may need to be written and debugged. Each generation of computer hardware and operating system usually requires an update of the software, which must then be validated before use. A suite of test data, for which correct values of common frequency stability measures are known, can be a valuable tool for checking the accuracy of frequency stability analysis software.
The time domain stability of a frequency source can be measured by either phase or frequency data. The former is normally expressed as x(t)=f(t)/2pn0, where n0 is the nominal frequency. This quantity has units of time, but is generally called "phase" to avoid confusion with the independent time variable, t. Frequency is normally expressed as fractional frequency, y(t)=[n(t)-n0]/n0=x'(t), which is dimensionless. When making stability measurements, it is preferable to take phase data, since it is the more fundamental quantity. The terms "frequency standard" and "clock" are often used interchangeably. A frequency source may be called a clock even though it does not contain any actual clock hardware, especially if it is used for timing purposes. The term "oscillator" is best used for an active source like a crystal oscillator rather than a passive device such as a cesium beam tube or rubidium gas cell frequency reference.
Preprocessing of the measurement data is often necessary before performing the actual analysis, which may require data averaging, or removal of outliers, frequency offset and drift [4].
Phase data can be modified for a longer averaging time by simply removing the intermediate points. This is accomplished for frequency data by calculating the average of each group of points.
Frequency offset may be removed from phase data by subtracting a line determined by the average of the first differences, or by a least-squares linear fit. An offset may be removed from frequency data by normalizing it to have an average value of zero.
Frequency drift may be removed from the phase data by a least-squares or 3-point quadratic fit [5], or by subtracting the average of the second differences. Frequency drift may be removed from frequency data by subtracting a least-squares linear fit, by subtracting a line determined by the first-differences of the frequency data or by calculating the drift from the difference between the two halves of the data. The latter, called here the bisection drift, is equivalent to the 3-point fit to the phase data.
Other, more specialized, methods of drift removal may also be used. For example, the frequency data may be fit to a particular model such as the log function of MIL-PRF-55310 [6]. The latter is particularly useful to describe the stabilization of a frequency source. In general, the objective is to remove as much of the deterministic behavior as possible, obtaining random residuals for subsequent noise analysis.
Phase data may be converted to frequency data by calculating the first differences of the phase data and dividing by the measurement interval or averaging time. Frequency data may be converted to phase data by piecewise integration, using the averaging time as the integration interval. Any gaps in the frequency data must be filled to obtain a continuous phase record.
The most common time-domain measures of frequency stability are as follows:
where the variances are functions of the averaging time, t. These quantities are not affected (except possibly for reasons of numerical precision) by the nominal frequency offset. They are (except for the Hadamard family) usually calculated after removal of frequency drift, and are normally expressed as their square roots, or deviations, ADEV, MDEV, TDEV, HDEV, TOTDEV, MTOTDEV, TTOTDEV and HTOTDEV. Each can be calculated from either phase or frequency data, which give the same result.
These calculations are reasonably fast on a modern computer with a math coprocessor, except, perhaps, for the total statistics. For a data set of several thousand points, the normal Allan variance calculation is practically instantaneous, and the overlapping Allan and total variance calculations take a second. Calculation of the modified total variance from phase data may take several seconds, while its calculation from frequency data requires a triply-nested loop that can take a minute. Faster algorithms than the obvious ones are available [12, 13, 21, 30], particularly if the data has no gaps. A complete stability run is commonly done over a range of averaging times by doubling the t at each successive analysis point for which there is sufficient data, although results at all t values can provide valuable insight into periodic interference.
A "classic'' suite of frequency stability test data is the set of nine 3-digit numbers from Annex 8.E of NBS Monograph 140 [14] shown in Table I. Those numbers were used as an early example of an Allan variance calculation. This frequency data is also normalized to zero mean by subtracting the average value, and then integrated to obtain phase values. A listing of the properties of this data set is shown in Table II. While nine data points are not sufficient to calculate large frequency averages, they are, nevertheless, a very useful starting point to verify frequency stability calculations since a small data set can easily be entered and analyzed manually. A small data set is also an advantage for detecting "off-by-one'' errors.
The larger frequency data test suite used here consists of 1000 pseudo-random frequency data points. It is produced by the following prime modulus linear congruential random number generator [15]:
ni+1 = 16807 ni Mod 2147483647
This expression produces a series of pseudo-random integers ranging in value from 0 to 2147483646 (the prime modulus, 231-1, avoids a collapse to zero). When started with the seed n0 = 1234567890, it produces the sequence n1 = 395529916, n2 = 1209410747, n3 = 633705974, etc. These numbers may be divided by 2147483647 to obtain a set of normalized floating-point test data ranging from 0 to 1. Thus the normalized value of n0 is 0.5748904732. A spreadsheet program is a convenient and reasonably universal way to generate this data. The frequency data set may be converted to phase data by assuming an averaging time of 1, yielding a set of 1001 phase data points. Similarly, frequency offset and/or drift terms may be added to the data. These conversions can also be done by a spreadsheet program.
The values of this data set will be uniformly distributed between 0 and 1. While a data set with a normal (Gaussian) distribution would be more realistic, and could be produced by summing a number of independent uniformly distributed data sets, or by the Box-Muller method [24], this simpler data set is adequate for software validation.
The statistics for the 1000-point test suite are shown in Table III. These values, reported to 7 significant figures, were obtained using IEEE 754 64-bit double-precision (15-digit) floating point arithmetic. While this reported precision is unwarranted for actual stability measures, it is useful for software validation. The theoretical expected value for the mean of a random variable uniformly distributed over the interval (0,1) is 0.5, and is independent of the averaging factor. The linear slope (per data interval) and the intercept are calculated as a least-squares linear regression fit. The standard deviation is that for the sample (not the population). The theoretical expected value for the standard deviation is 1/Ö12 = 0.2886751. The normal Allan deviation, sy(t ), is calculated for the full data set without averaging (t = t0) using adjacent differences. For white frequency noise, it is equal to the standard deviation. The modified Allan deviation, Mod sy(t ), is, by definition, equal to the normal Allan deviation for an averaging time equal to that of the basic data. The overlapping Allan deviation, calculated using fully-overlapping samples (every available difference at a certain averaging time) is also equal to the normal Allan deviation for t = t0. The time deviation, sx(t ) is simply the modified Allan deviation multiplied by t/Ö3. The total variance uses a reflection method [22] that significantly improves the confidence of the stability estimate at long averaging times. It has the same expected value as the Allan variance for white and flicker PM noise and white FM noise. Bias corrections of the form 1-ct/(T-t), where T is the record length, need to be applied for flicker and random walk FM noise, where c = 0.240 and 0.375 respectively [23].
It is not uncommon to have gaps and outliers in a set of raw frequency stability data. Missing or erroneous data may occur due to power outages, equipment malfunctions and interference. For long-term tests, it may not be possible or practical to repeat the run, or otherwise avoid such bad data points. Usually the reason for the gap or outlier is known. It is particularly important to explain all phase discontinuities. Plotting the data will often show the bad points, which may have to be removed before analysis to obtain meaningful results.
A simple, yet effective, technique for finding outliers is to compare each frequency data point yi with the median value, m, of the data set plus or minus some multiple of the absolute median deviation (MAD):
MAD = Median { | yi - m | / 0.6745}
where m = Median { yi }, and the factor 0.6745 makes the MAD equal to the standard deviation for normally distributed data [16]. These median statistics are more robust because they are insensitive to the size of the outliers. Outlier detection is normally applied only to frequency data.
More elaborate techniques exist for the recognition of outliers in marginal cases [16, 17]. A particularly effective means is statistical comparison of each data point against an optimum predictor based on an appropriate noise model.
Often a bad data point is replaced with a gap. The gaps should be kept in the record because they serve as "place-keepers'' in time, and because "truth-in-packaging'' may require them to be identified. A value of zero is often used as an obvious and unique way to indicate a gap, especially in fractional frequency data, where a value of zero almost never appears. It is also an easy value to test for. However, a value of zero does occur at the beginning and end of a set of normalized phase data, so while a zero is suitable to indicate an embedded gap in phase data, it is not unique as the first or last point.
A fractional frequency value of zero can occur when two adjacent phase values are the same (as might happen with limited-precision short-term phase data for a noisy source having a small frequency offset). Treating this case as a frequency gap is reasonable, but it can cause problems in calculations using the phase data.
Stability analysis algorithms can be modified to handle gaps. Two sample variances can simply be formed for the available pairs, taking into account the actual number of analysis points. Averages can be formed where there is at least one point within the group. Otherwise a gap is inserted into the averaged data. Phase-frequency conversions can also be written to handle gaps. In a plot, missing data is best shown as a gap without a line connecting the adjacent points.
Optionally, a gap may be replaced by an interpolated value. While this may be desirable in some cases, it masks the existence of the missing data, and creates a fictitious value. Filling in gaps has the advantage, however, that the plotting method and stability analysis calculations do not have to have provisions to handle gaps. Gap filling is also necessary when performing a frequency to phase conversion to preserve phase continuity.
A phase jump, Dx, corresponds to a frequency spike of y=Dx/t. Such an event will have a t-1/2 stability characteristic, and thus appear as white FM noise at a level of s2y(t)=Dx2/t(T-t) where T is the record length and T>>t [26]. It is often indicative of a problem in the clock, transmission path or measurement system and should be investigated. This also shows the importance of visual inspection of the phase record.
Frequency jumps can also be a problem for stability analysis. Intuitively, a frequency jump is an indication that the statistics of the device being measured are not stationary. It may be necessary to divide the record into two portions before and after the jump and analyze them separately. A jump may be defined and recognized by moving a sliding window through the frequency data, looking for a change in the average value between the first and last halves of the window. The change can be judged in relation to the scatter of the data.
A one column vector is all that is required for a phase or frequency data array. Because the data points are equally spaced, no time tags are necessary. While time tagging may be needed for archival storage of clock measurements, a vector of extracted gap-filled data is sufficient for analysis.
There are relatively few numerical precision issues relating to the analysis of frequency stability data. One obvious case, however, is phase data for a highly stable frequency source having a relatively large frequency offset. The raw phase data will be essentially a straight line (representing the frequency offset), and the instability information is contained in the small deviations from the line. A large number of digits must be used unless the frequency offset is removed by subtracting a linear term from the raw phase data. Similar considerations apply to the quadratic phase term (linear frequency drift).
Many frequency stability measures involve averages of first or second differences. Thus, while their numerical precision obviously depends upon the variable digits of the data set, there is little error propagation in forming the summary statistics.
Data plotting is often the most important step in the analysis of frequency stability. Visual inspection can provide vital insight into the results, and is an important "preprocessor'' before numerical analysis. A plot also shows much about the validity of a curve fit.
Phase data is generally plotted as line segments connecting the data points. This presentation properly conveys the integral nature of the phase data. Frequency data is often plotted the same way, simply because that is the way plotting is usually done. But a better presentation is a flat horizontal line between the frequency data points. This shows the averaging time associated with the frequency measurement, and mimics the analog record from a frequency counter. As the density of the data points increases, there is essentially no difference between the two plotting methods. In a plot, missing data should be shown as a gap without a line connecting the adjacent points.
Stability plots generally take the form of graphs of log s versus log t, often with error bars to shown the precision of the results. The slope of the sy(t) characteristic depends on the type of noise. It is customary to show points at octave increments of t. These are equally spaced on the log scale, and are the result of successive averaging by a factor of two. Such a run usually ends when there are too few analysis points (say < 7) for reasonable confidence. A run for all possible t values, while slow, can provide valuable information since it is, in effect, a form of spectral analysis that can show power-law spectra and periodic instabilities such as environmental effects.
Several approaches exist for the setting of error bars on a stability plot to indicate the precision of the results. A rough approximation to a standard 1-sigma confidence interval can obtained by simply dividing the point value by the square root of the number of analysis points. This approximation degenerates for a small number of degrees of freedom. More exact single and double-sided confidence intervals can be determined by the noise and variance type [2, 8, 18, 23, 25], as shown in Table IV.
It is often desirable to have a means of identifying the type of noise that is being analyzed, and to be able to fit it to a power law noise model. Noise recognition can generally be accomplished by using the B1 bias function (the ratio of the standard variance to the Allan variance) and the R(n) ratio function (the ratio of the modified Allan variance to the normal Allan variance) [30]. These functions can be calculated by the methods described in Reference [1]. Power law noise can be modeled over a range of averaging times by fitting a line to the results of an Allan deviation stability analysis on a log s versus log t plot.
It is valuable to have a means of generating simulated power law clock noise having the desired noise type (white phase, flicker phase, white frequency, flicker frequency and random walk frequency), Allan deviation, frequency offset and frequency drift. This can serve as an additional means to validate stability analysis software, particularly for checking numerical precision and noise recognition and modeling. An excellent method for power-law noise generation is described in Reference 19. This reference also provides very useful analysis insights.
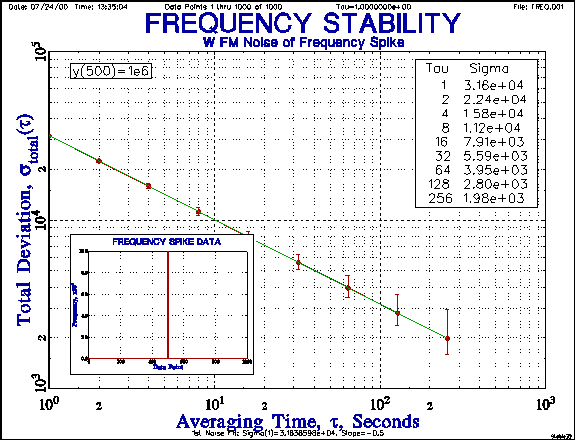
Another way to simulate white FM noise is to take advantage of the fact that the Allan deviation of a frequency record having large spike (a phase step) has a t-1/2 characteristic [26]. Thus adding a single large (say 106) central outlier to the same 1000-point t=1 test suite discussed above will give a data set with sy(t)=[(106)2/(1000-1)]1/2 = 3.16386e4 [See plot].
Several methods are available to validate frequency stability analysis software:
There is a continuing need to validate the custom software used to analyze time domain frequency stability. The suite of test data presented here, along with the other suggestions made, can help assure that correct results are obtained.
The author thanks Messrs. D.W. Allan, L.S. Cutler, S.R. Stein and F.L. Walls for their help in checking the results presented here. Any remaining errors are my responsibility alone.
|
NBS Monograph 140, Annex 8.E Test Data |
|||
|
Point # |
Frequency |
Normalized Frequency |
Phase (t =1) |
|
1 |
892 |
103.11111 |
0.00000 |
|
2 |
809 |
20.11111 |
103.11111 |
|
3 |
823 |
34.11111 |
123.22222 |
|
4 |
798 |
9.11111 |
157.33333 |
|
5 |
671 |
-117.88889 |
166.44444 |
|
6 |
644 |
-144.88889 |
48.55555 |
|
7 |
883 |
94.11111 |
-96.33333 |
|
8 |
903 |
114.11111 |
-2.22222 |
|
9 |
677 |
-111.88889 |
111.88889 |
|
10 |
|
|
0.00000 |
|
NBS Monograph 140, Annex 8.E Test Data Statistics [Download] |
||
|
Averaging Factor |
1 |
2 |
|
# Data Points |
9 |
4 |
|
Maximum |
903 |
893.0 |
|
Minimum |
644 |
657.5 |
|
Average |
788.8889 |
802.875 |
|
Median |
809 |
830.5 |
|
Linear Slope |
- 10.20000 |
-2.55 |
|
Intercept |
839.8889 |
809.25 |
|
Standard Deviation [1] |
100.9770 |
102.6039 |
|
Normal Allan Deviation |
91.22945 |
115.8082 |
|
Overlapping Allan Deviation |
91.22945 |
85.95287 |
|
Modified Allan Deviation |
91.22945 |
74.78849 |
|
Total Deviation |
91.22945 |
98.31100 |
|
Hadamard Deviation |
70.80608 |
116.7980 |
|
Time Deviation |
52.67135 |
86.35831 |
Table II Notes:
[1] Sample (not population)
standard deviation.
|
1000-Point Frequency Data Set [Download] |
||||
|
Averaging Factor (m) |
1 |
10 |
100 |
|
|
# Data Points |
1000 |
100 |
10 |
|
|
Maximum |
9.957453e-01 |
7.003371e-01 |
5.489368e-01 |
|
|
Minimum |
1.371760e-03 |
2.545924e-01 |
4.533354e-01 |
|
|
Average [1] |
4.897745e-01 |
4.897745e-01 |
4.897745e-01 |
|
|
Median |
4.798849e-01 |
5.047888e-01 |
4.807261e-01 |
|
|
Linear Slope [2,3] |
6.490910e-06 |
5.979804e-05 |
1.056376e-03 |
|
|
Intercept [3] |
4.865258e-01 |
4.867547e-01 |
4.839644e-01 |
|
|
Bisection Slope [2] |
-6.104214e-06 |
-6.104214e-05 |
-6.104214e-04 |
|
|
1st Difference Slope [2] |
1.517561e-04 |
9.648320e-04 |
1.011791e-03 |
|
|
Log Fit [2,4] |
a |
5.577220e-03 |
5.248477e-03 |
7.138988e-03 |
|
y(t)=a ln (bt+1)+c |
b |
9.737500e-01 |
4.594973e+00 |
1.420429e+02 |
|
c |
4.570469e-01 |
4.631172e-01 |
4.442759e-01 |
|
|
y'(t)=ab/(bt+1) |
Slope at end |
5.571498e-06 |
5.237080e-05 |
7.133666e-04 |
|
Standard Deviation [5] |
2.884664e-01 |
9.296352e-02 |
3.206657e-02 |
|
|
Normal Allan Deviation [6] |
2.922319e-01 |
9.965736e-02 |
3.897804e-02 |
|
|
Overlapping Allan Deviation [8] |
2.922319e-01 |
9.159953e-02 |
3.241343e-02 |
|
|
Modified Allan Deviation [7,8] |
2.922319e-01 |
6.172376e-02 |
2.170921e-02 |
|
|
Time Deviation [8] |
1.687202e-01 |
3.563623e-01 |
1.253382e-00 |
|
|
Hadamard Deviation |
2.943883e-01 |
1.052754e-01 |
3.910860e-02 |
|
|
Overlapping Hadamard Dev. |
2.943883e-01 |
9.581083e-02 |
3.237638e-02 |
|
|
Total Deviation [9] |
2.922319e-01 |
9.134743e-02 |
3.406530e-02 |
|
|
Modified Total Deviation |
2.418528e-01 |
6.499161e-02 |
2.287774e-02 |
|
|
Time Total Deviation |
1.396338e-01 |
3.752293e-01 |
1.320847e+00 |
|
|
Hadamard Total Deviation [10] |
2.943883e-01 |
9.614787e-02 |
3.058103e-02 |
|
Table III Notes:
[1] Expected value = 0.5.
[2] All slopes are per interval.
[3] Least-squares linear fit.
[4]
Exact results will depend on iterative algorithm used. Data not suited to log
fit.
[5] Sample (not population) standard deviation. Expected value = 1/12
= 0.2886751.
[6] Expected value equal to standard deviation for white FM
noise.
[7] Equal to normal Allan deviation for averaging factor = 1.
[8] Calculated with listed averaging factors from the basic tau=1 data set.
[9] Calculated using doubly reflected TOTVAR method.
[10] Hadamard total deviation equal to overlapping Hadamard deviation at m=1.
|
Error Bars for n=1000 Point Data Set with Averaging Factor=10 |
|||||||
|
Allan Deviation |
Noise |
Confidence Interval |
|||||
|
Type |
# |
Value |
Ratio |
Type |
Value |
C2 |
Remarks |
|
Normal |
99 |
9.965736e-02 |
B1= 0.870 |
W FM [1] |
CI = 8.713870e-03 [2,3] |
+/-1s error bars |
|
|
Overlapping |
981 |
9.159953e-02 |
W FM |
Max sy(t) = 1.014923e-01 |
119.07 |
+95% CI |
|
|
# C2df = |
Max sy(t) = 1.035201e-01 |
114.45 |
+/-95% CI |
||||
|
146.177 |
Min sy(t) = 8.223942e-02 |
181.34 |
|||||
|
Modified [4] |
972 |
6.172376e-02 |
R(n) = 0.384 |
W FM [5] |
|||
Table IV Notes:
[1] Theoretical B1=1.000 for W FM
noise and 0.667 for F and W PM noise.
[2] Simple, noise-independent CI
estimate = sy(t)/ÖN = 1.001594e-02.
[3] This CI
includes kafactor that
depends on noise type:
|
Noise |
a |
ka |
|
W PM |
2 |
0.99 |
|
F PM |
1 |
0.99 |
|
W FM |
0 |
0.87 |
|
F FM |
-1 |
0.77 |
|
RW FM |
-2 |
0.75 |
[4] BW factor =2 p f h
t0 =10. Applies only to F PM
noise.
[5] Theoretical R(n) for W FM noise = 0.500 and 0.262 for F PM
noise.
Last Revised: 07/03/02
{kind=link}